TensorFlow에서는 .csv 형식의 데이터 파일을 주로 사용한다.
파일을 읽는 방식은 다음 코드와 같다.
xy = numpy.loadtxt('data-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
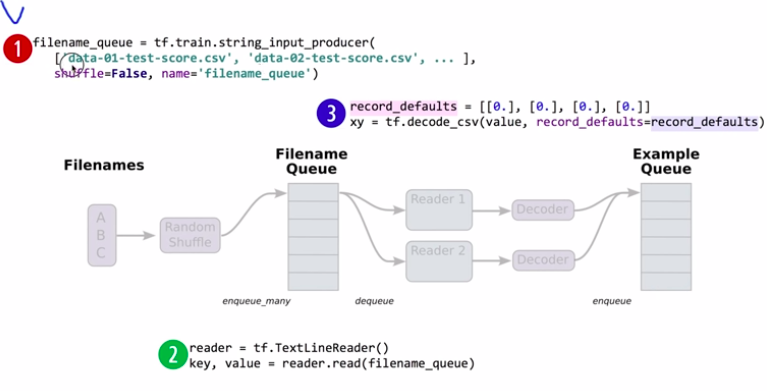
여러개의 파일들을 training에 사용하고 싶을 때, TensorFlow에서 제공하는 Queue Runners라는 기능을 사용할 수 있다.
원리는 다음과 같다.
1. 파일들의 리스트를 만들어준다.
2. Reader를 사용하여 파일들을 읽는다.
3. decode_csv를 이용하여 데이터 타입, shape을 정의한다.
4. tf.train.batch(데이터를 펌핑하는 기능)을 사용하여 한 번에 가져올 크기를 정한다.
5. 세션을 생성한다.
코드는 아래와 같다. 복잡해 보이지만 일반적으로 TensorFlow에서 사용하는 코드이니 이런게 있구나 정도로 이해하면 된다.
filename_queue = tf.train.string_input_producer(
['data-01-test-score.csv', 'data-02-test-score.csv'], shuffle=False, name='filename_queue')
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[0.], [0.], [0.], [0.]]
xy = tf.decode_csv(value, record_defaults=record_defaults)
# collect batches of csv in (한 번에 몇 번 펌프질할지 결정함)
train_x_batch, train_y_batch = tf.train.batch([xy[0:-1], xy[-1:]], batch_size=10)
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3,1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis
hypothesis = tf.matmul(X, W) + b
# Simplified cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Minimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
# Launch the graph in a session.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(2001):
x_batch, y_batch = sess.run([train_x_batch, train_y_batch])
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train],
feed_dict = {X:x_batch, Y:y_batch})
if step % 10 == 0 :
print(step, "Cost:", cost_val,"\nPrediction:\n", hy_val)
coord.request_stop()
coord.join(threads)※ inflearn 모두를 위한 딥러닝 강좌를 듣고 정리한 내용입니다.
'Deep Learning' 카테고리의 다른 글
| Multinomial의 개념과 Softmax Classification 구현 (0) | 2019.04.21 |
|---|---|
| Logistic Classification의 HCG (0) | 2019.04.21 |
| 여러 feature의 linear regression (0) | 2019.04.15 |
| Linear Regression의 cost 최소화 알고리즘의 원리 (0) | 2019.04.14 |
| Linear Regression의 Hypothesis와 cost (0) | 2019.04.14 |

